前言
本篇博客介绍ICIP2016发表的论文 End-to-end crowd counting via joint learning local and global count。 本篇论文主要创新在于将人群计数转化为区域内计数任务,为前端网络的输出赋予了明确含义。 注:正文包括笔者对原论文的翻译和自己的理解,请读者注意区分人称。
Abstract
由于拥挤,外观变化和透视变形,在拥挤的场景中进行人群计数是一项非常具有挑战性的任务。当前的人群计数方法通常在一系列互相重叠的图像块上进行操作(就是在分辨率比较大的原图上有重叠的采样),然后对patch进行求和以获得最终计数。在本文中,我们提出了一种端到端卷积神经网络(CNN)架构,该架构以整个图像为输入并直接输出计数结果。当利用重叠区域上的共享计算时,我们的方法在预测局部和全局计数时会充分利用上下文信息。我们首先将图像输入到经过预先训练的CNN中,以获取一组高级特征。然后,使用具有LSTM将特征映射到局部计数。我们在几个具有挑战性的人群计数数据集上进行了实验,这些数据集获得了最新的结果并证明了我们方法的有效性。
Introduction
本文提出了一种端到端的CNN模型来处理人群图像中的计数任务。我们的方法不是将图像分成小块,而是将整个图像作为输入,并直接输出最终的图像计数。 结果,我们的方法利用了重叠区域上的共享计算,并结合了多个处理阶段以降低复杂性。要学习端到端模型,一种直接的方法是直接回归输入图像的全局计数。但是整体图像比图像patch包含更多的背景噪声和更少的目标区域(这里的更少的目标区域是从目标区域面积占整体面积的比率而言),很难收敛。 为了解决这个问题,我们提出同时学习局部计数,这可以看作是学习patch级别计数模型,而局部计数可以帮助加速模型训练。
END-TO-END CROWD COUNTING
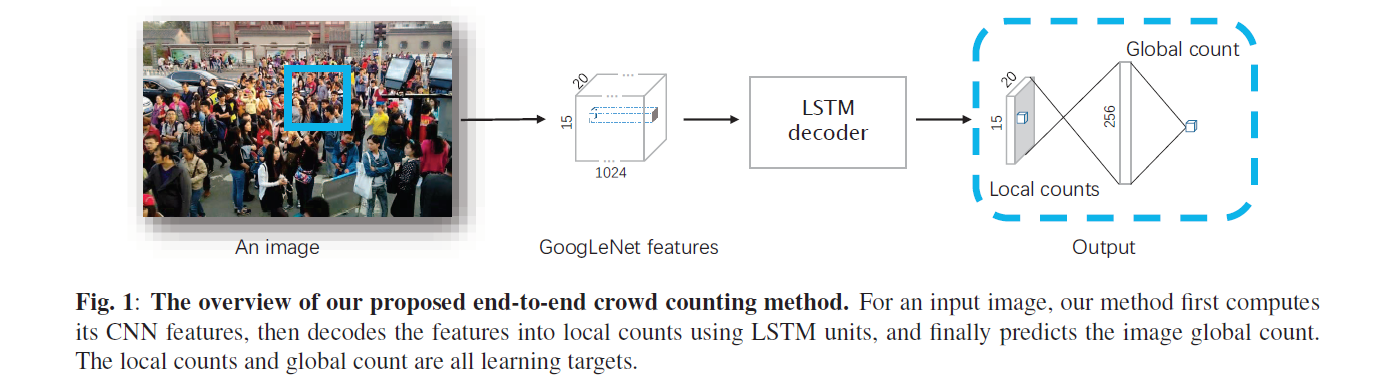
网络由三个部分组成,一个GoogleLeNet提取特征,LSTM 映射特征到局部计数,全连接层映射到最终计数。假设第一个部分的输出是一个维度为k × w × h的特征,每个position代表原图这个小块内的局部特征。网络通过加权的loss同时优化局部计数和全局计数。
Local Count
这里着重讲一下局部计数的定义。
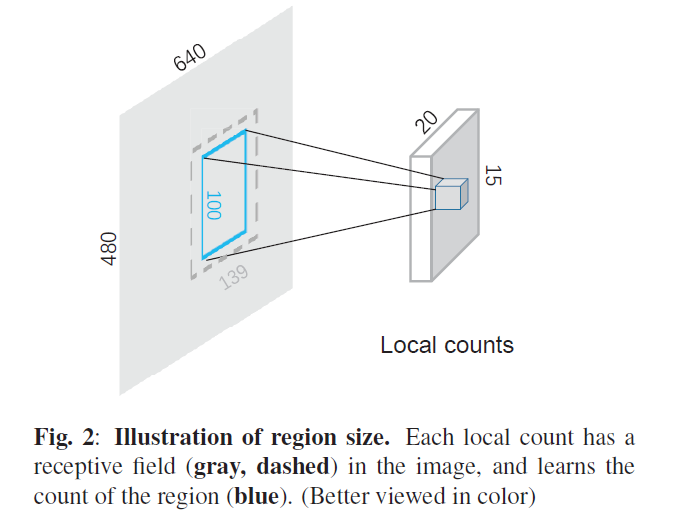
如图,GoogleLeNet的感受野是139,也就是说在输出的$1024 \times 20 \times 15$的特征中,每个位置对应了原图$139 \times 139$的区域,但作者让其对应至这个区域中心$100\times100$的计数。