前言
本篇博客介绍CVPR2018发表的论文 CSRNet。 推荐一个基于pytorch框架的简洁开源实现Github,建议对照学习。 注:正文包括笔者对原论文的翻译和自己的理解,请读者注意区分人称。
Abstract
本文提出了一种称为CSRNet的用于拥挤场景计数的网络,该方法可以理解高度拥挤的场景并进行准确的计数估计以及生成高质量密度图。我们提出的CSRNet由两个主要组件组成:卷积神经网络(CNN)作为2D特征提取的前端,而扩张卷积网络则作为后端,后者使用扩张卷积核提供更大的感受野并替换池化操作。 CSRNet由于具有纯卷积结构,因此是易于训练的模型。 我们在四个数据集(ShanghaiTech数据集,UCF_CC_50数据集,WorldEXPO’10数据集和UCSD数据集)上验证了CSRNet,并体现了最优性能。在ShanghaiTech_Part_B数据集中,CSRNet的平均绝对误差(MAE)比以前的最新方法低47.3%。我们将应用领域扩展至其他目标计数,例如TRANCOS数据集中的车辆计数。结果表明,与以前的最新技术方法相比,CSRNet显着提高了输出质量,MAE降低了15.4%。
Introduction
首先,文章点明了基于密度图估计的深度方法的挑战所在:1)MSE这一类逐像素回归的损失函数,会使得网络尽可能生成逐点平滑的密度图,这和实际情况往往不符合。2)不规则的人群聚集。3)变化的相机透视关系。 然后文章吐槽了一下MCNN。第一,MCNN训练时间比较长。第二,MCNN本意是通过各分支不同大小的卷积核 学习到不同尺度的信息,但实际上把训练好的MCNN的每一列拿出来测试,发现错误率曲线是非常相似的,说明每一列学到的信息实际上相同。
Contributions of this paper
- 使用全卷积网络,去掉所有pooling操作,避免特征图分辨率在Backbone之后继续降低:
- 全部卷积核尺寸为3$\times $3
- 使用空洞卷积作为网络后端。
Related Work
略
Method
CSRNet 架构
使用VGG-16的前13层加一个$1\times 1$卷积作为前端backbone.
为了避免特征图分辨率在后端继续下降,使用空洞卷积作为后端。
空洞卷积
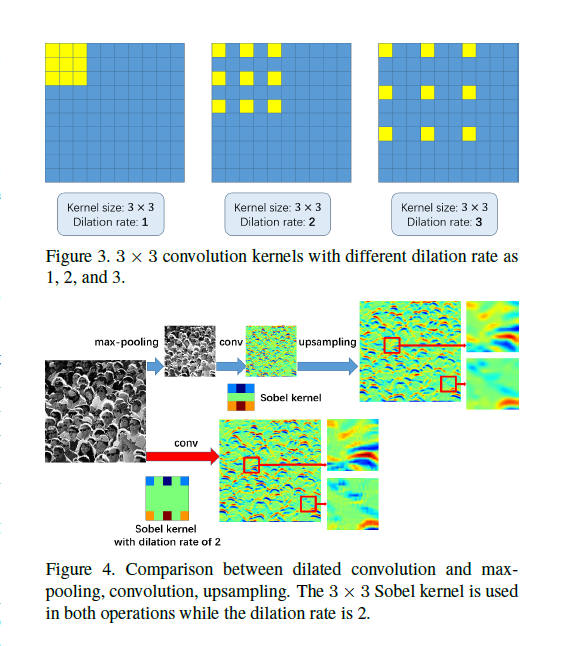
空洞卷积看一张示意图就明白了:
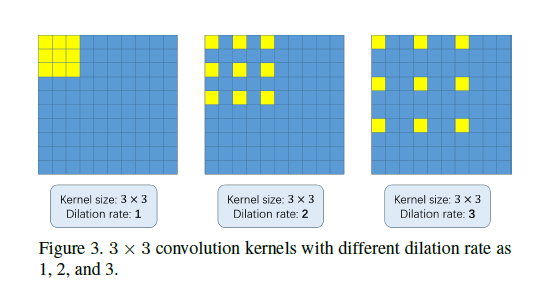
就是在普通的卷积核里面塞上空洞,这样把它变成更大的卷积核,然而实际运算量不变。(认为空洞不参与计算)
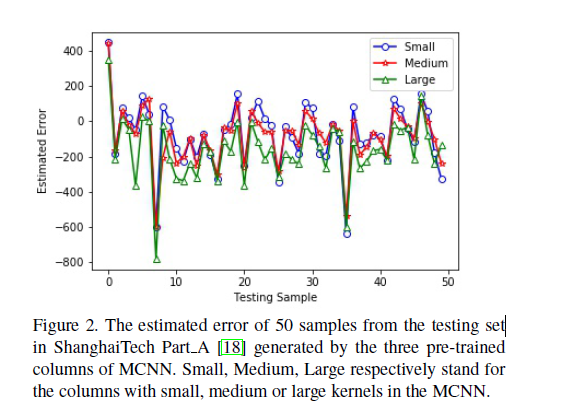
文章认为空洞卷积出来的特征图包含更多细节,如下图:
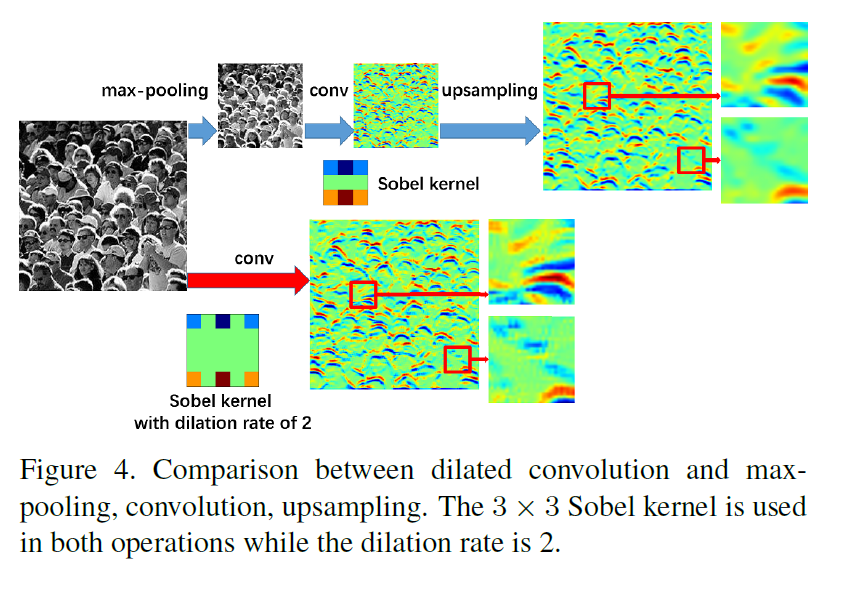
这个地方我不敢苟同,图中放大的部分不是细节,而是空洞卷积造成的网格效应。由于空洞卷积的计算方式类似于棋盘格式,某一层得到的卷积结果,来自上一层的独立的集合,没有相互依赖,因此该层的卷积结果之间没有相关性,即局部信息丢失。但是为什么CSRNet有效呢?我觉得是空洞卷积的这个缺点恰好符合了人群计数的一个特点,那就是密集的多峰(每个人头的位置为一个峰),空洞卷积恰好跳过了峰值以外的位置,而将各个峰值位置的信息结合了起来。